Title: "Mastering Information Retrieval: The LLM Augmentation Journey"

SLIDE1 |

SLIDE2 |

SLIDE3 |

SLIDE4 |

SLIDE5 |

SLIDE6 |

SLIDE7 |

SLIDE8 |

SLIDE9 |

SLIDE10 |

SLIDE11 |

SLIDE12 |
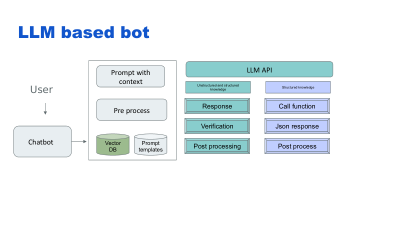
SLIDE13 |

SLIDE14 |

SLIDE15 |

SLIDE16 |

SLIDE17 |

SLIDE18 |

SLIDE19 |

SLIDE20 |

SLIDE21 |

SLIDE22 |

SLIDE23 | |
RAG (Retrieval Augmentation Generation)RAG, short for Retrieval Augmentation Generation, is a powerful model that combines the capabilities of retrieval, augmentation, and generation in natural language processing tasks. It is designed to enhance the performance of question-answering systems and text generation models by integrating these three key components. How RAG Works:RAG operates in three main stages:
Role of Vector DB:Vector DB plays a crucial role in the functioning of RAG by providing a structured and efficient way to store and retrieve vector representations of text data. These vector embeddings capture the semantic meaning and relationships between words, sentences, or documents, enabling RAG to perform similarity-based searches and context-aware retrievals. By leveraging Vector DB, RAG can quickly access and manipulate vectorized representations of textual information, facilitating the retrieval and augmentation processes. This integration enhances the model's ability to understand and generate natural language responses with improved accuracy and relevance. |
||||||||||
LLM Retrieval Augment GenerationLLM Retrieval Augment Generation is a multi-stage process that involves various sub-stages to enhance the retrieval and generation of information. Below are the four main stages along with their sub-stages:
Pre-RetrievalIn the Pre-Retrieval stage, the focus is on preparing the data for efficient retrieval. This involves indexing the data, manipulating queries to improve search results, and modifying the data structure for better organization. RetrievalThe Retrieval stage involves the actual search process and ranking of results based on relevance. Search algorithms are applied to retrieve information, and ranking algorithms determine the order in which results are presented to the user. Post-RetrievalAfter retrieving the initial results, the Post-Retrieval stage focuses on refining the results further. This may involve re-ranking the results based on additional criteria and applying filters to narrow down the information to the most relevant. GenerationIn the Generation stage, the emphasis is on enhancing the retrieved information, customizing it to fit specific user needs, and synthesizing content to provide a more comprehensive output. This stage aims to generate augmented content that adds value to the retrieved information. |
||||||||||
Rag-for-structured-and-unstru Rag-for-strucutred-data Sql-stats-genai-rag-methods-f